Applicable Products
QTS, QuTS hero
Container Station
Scenario
You want to run large language models (LLMs) locally on your QNAP NAS for private AI chat, code assistance, or document analysis without sending data to the cloud. Ollama is the most popular and beginner-friendly inference engine for this purpose. This tutorial explains how to deploy Ollama on the QNAP NAS using Container Station.
System Requirements
| Requirement | Detail |
|---|
| QNAP App | Container Station 3.x or later |
| NAS Architecture | x86_64 (Intel or AMD CPU)
(Only a few ARM-based models are supported.) |
| Memory | - At least 8 GB (for 3B models)
- At least 16 GB (for 7B models)
|
| Storage Space | - At least 20 GB of extra free storage space in addition to the model file size.
- Use an SSD volume if possible.
|
| GPU (Optional) | Compatible NVIDIA GPUs (see the compatibility list)
GPU should be set to Container Station Mode in the Control Panel. |
Warning
OOM (Out of Memory) Risk
Ollama will attempt to load the entire model into memory by default. If your NAS has only 8–16 GB of RAM, loading a 14B or larger model may exhaust system memory, causing NAS services to become unresponsive or the system to restart.
Data Loss Risk
If you do not mount a persistent volume for /root/.ollama, all downloaded models and configuration will be lost when the container is removed or recreated. Always follow the volume mounting instructions in this tutorial.
Best Practice
- Check the model size against your available RAM in advance.
- Set memory limits to cap container memory usage.
- Start with small models (1B or 3B) and assess system stability before attempting larger models.
Procedure
Method 1: CPU-Only Deployment (No GPU Required)
Create storage folders.
Open File Station and create the following folder to store Ollama model data:
/share/Container/ollama
 Screenshot: File Station — creating the Ollama folder under /share/Container/
Screenshot: File Station — creating the Ollama folder under /share/Container/
Best Practice
If your NAS has an NVMe SSD cache or SSD volume, create this folder on the SSD. Model loading speed improves by up to 10 times compared to HDDs.
Create a Docker Compose file.
In Container Station, go to Applications > Create. Name the application ollama and paste the following YAML:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
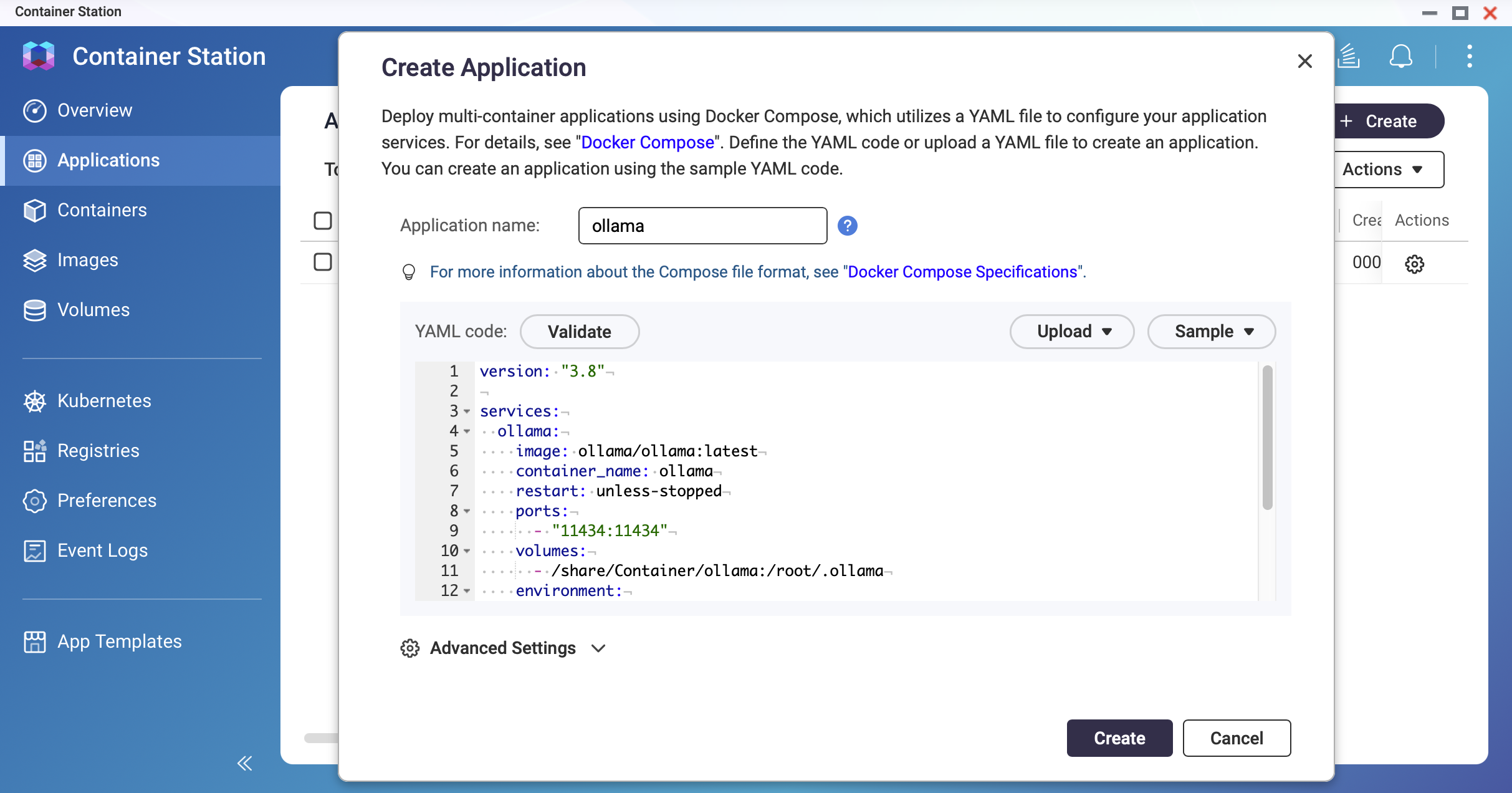 Screenshot: Container Station — Application creation screen with YAML editor
Screenshot: Container Station — Application creation screen with YAML editor
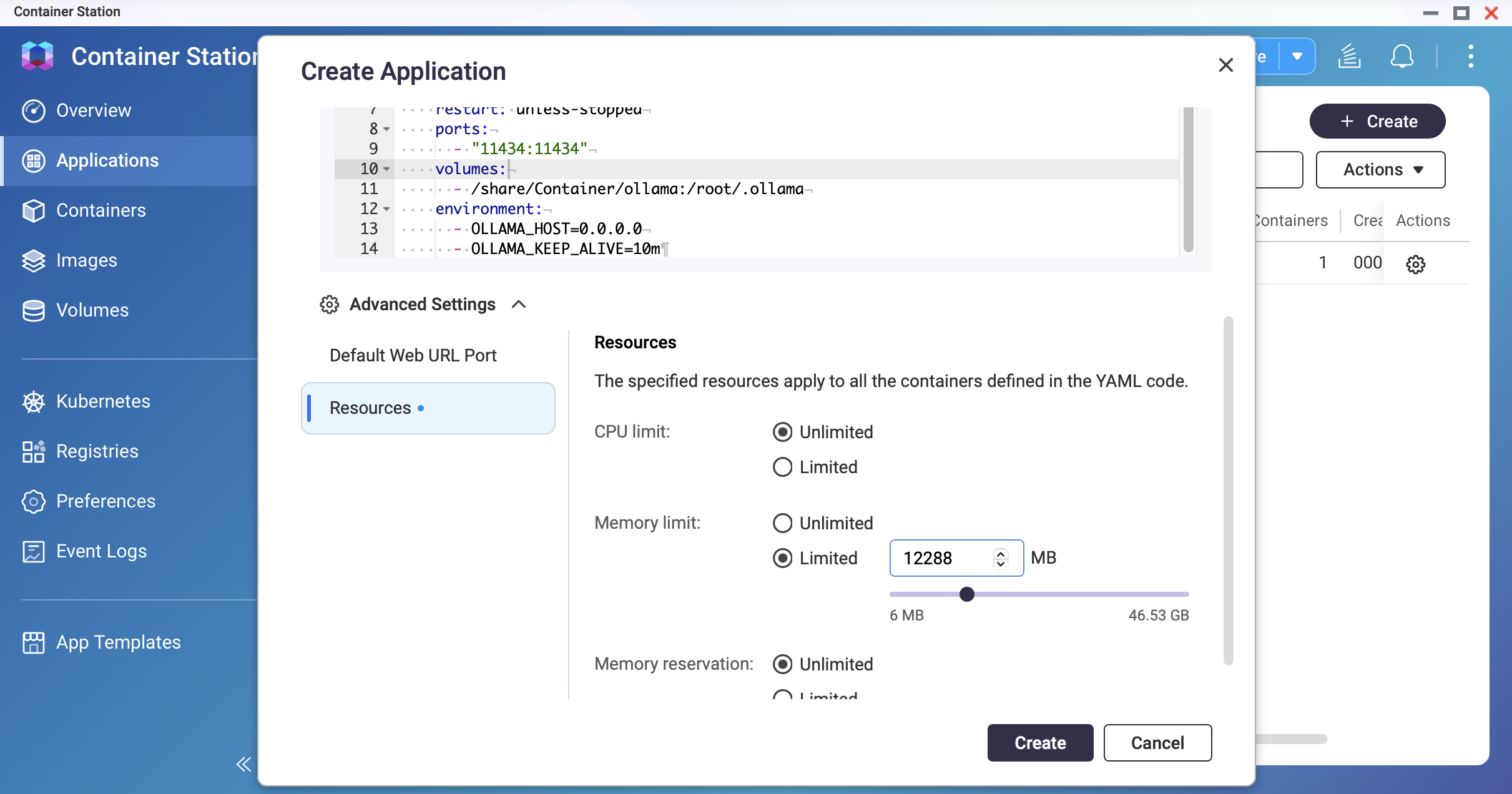 Screenshot: Container Station — Set the memory limit
Screenshot: Container Station — Set the memory limit
Deploy the container.
Click Create. Container Station will pull the Ollama image and start the container. Wait until the status shows Running.
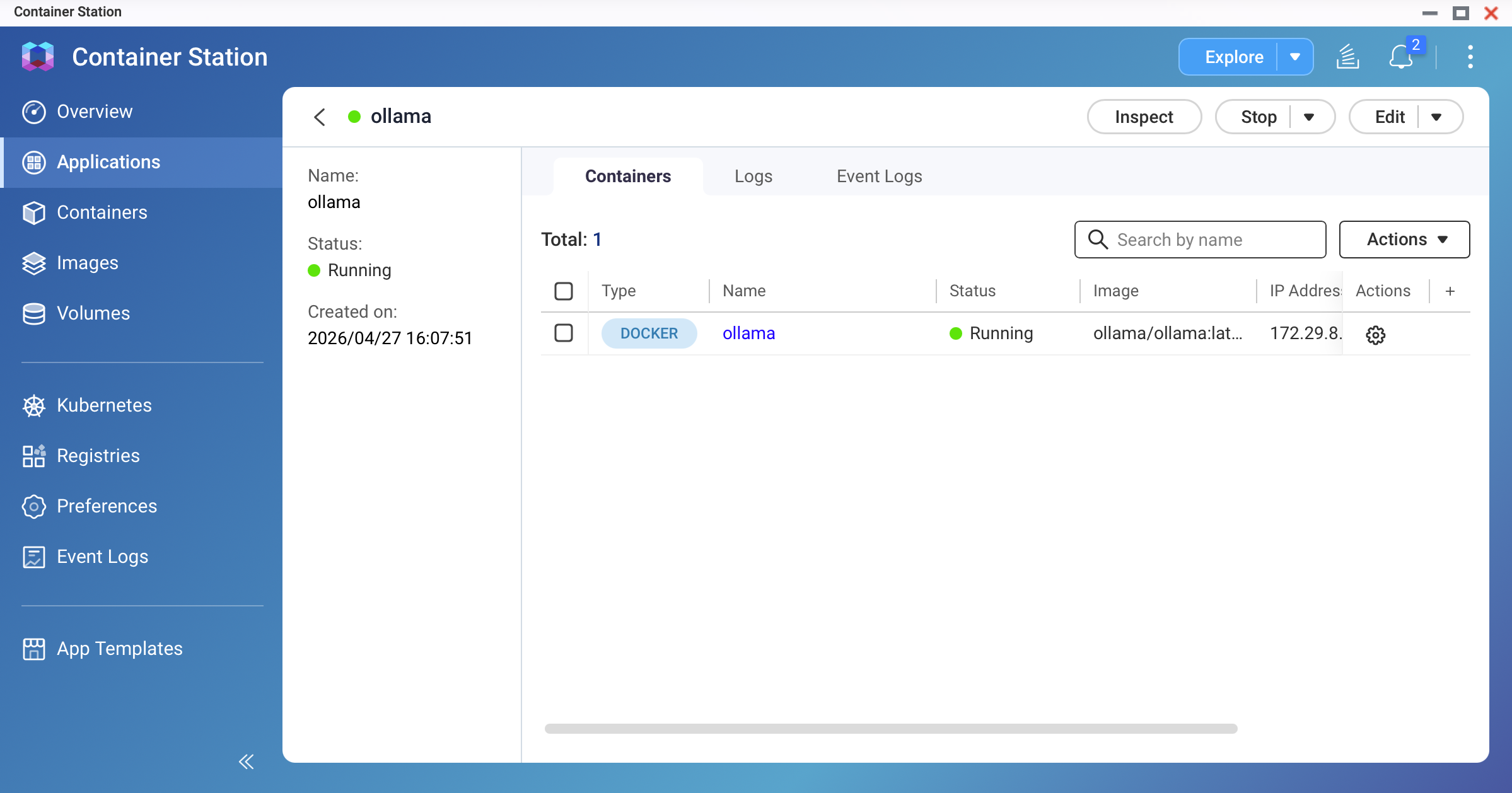 Screenshot: Container Station — ollama container showing "Running" status
Screenshot: Container Station — ollama container showing "Running" status
Pull your first model.
Open the container's Terminal (or SSH into your NAS and exec you Docker) and run:
# For a lightweight 3B model (recommended for first test):
ollama pull llama3.2:3b
# For a standard 9B model (requires 16 GB+ RAM):
ollama pull qwen3.5:9b
The download may take several minutes depending on your internet speed. A 9B Q4_K_M model is approximately 4–7 GB.
Note
- Verify you have sufficient disk space before pulling. Use
ollama list to check existing models and their sizes. - For ARM-based NAS models, we recommend starting with the <1B model to monitor memory usage.
Test the model.
In the container terminal, run:
ollama run qwen3.5:9b
Type a prompt and confirm that you receive a response. Type /bye to exit.
Method 2: NVIDIA GPU-Accelerated Deployment
Note
Additional prerequisites for GPU Mode:
- NVIDIA GPU installed and detected by QTS/QuTS hero
- GPU set to Container Station Mode in the Control Panel
- NVIDIA GPU Driver and NvKernelDriver installed from App Center
Use the GPU-enabled Docker Compose configuration.
Replace the YAML from Method 1 with the following:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
- NVIDIA_VISIBLE_DEVICES=all
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
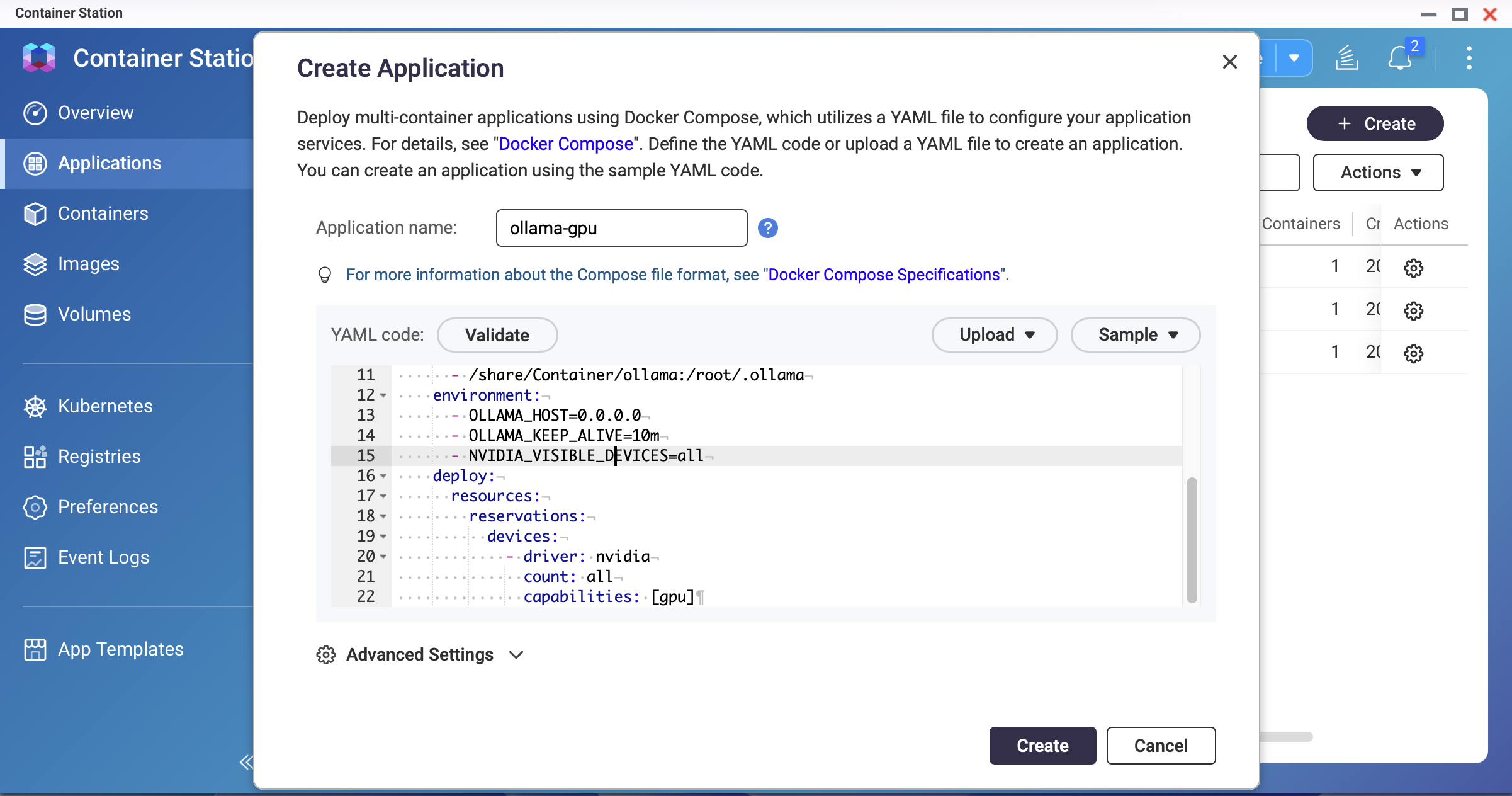 Screenshot: Container Station — GPU-enabled Docker Compose YAML
Screenshot: Container Station — GPU-enabled Docker Compose YAML
Note
QNAP's bundled NVIDIA drivers may be older than the latest release. If the container fails to start with GPU enabled, check the driver version with nvidia-smi on the host and ensure it is compatible with the Ollama image version
Deploy and verify GPU access.
After the container starts, open its terminal and run:
nvidia-smi
You should see your GPU model, driver version, and memory information.
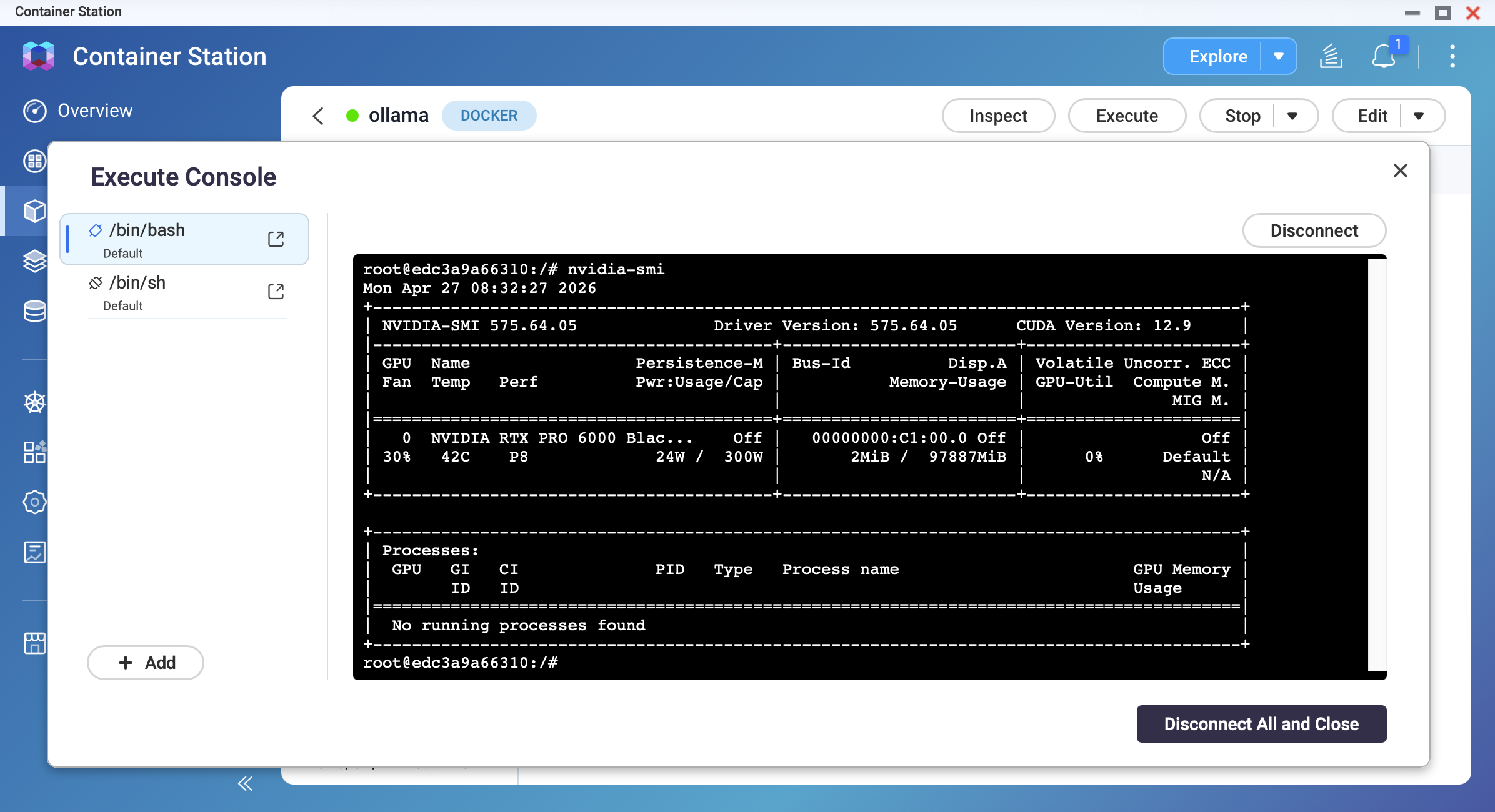
Pull a model and confirm GPU acceleration.
ollama pull qwen3.5:9b
ollama run qwen3.5:9b
While the model is generating a response, open another terminal and run nvidia-smi. You should observe GPU memory usage and GPU utilization increasing.
Result
After completing this tutorial, you will have:
- Ollama running on your QNAP NAS at
http://<NAS-IP>:11434 - Model data persisted in
/share/Container/ollama (survives container rebuilds) - A working LLM accessible via the Ollama API
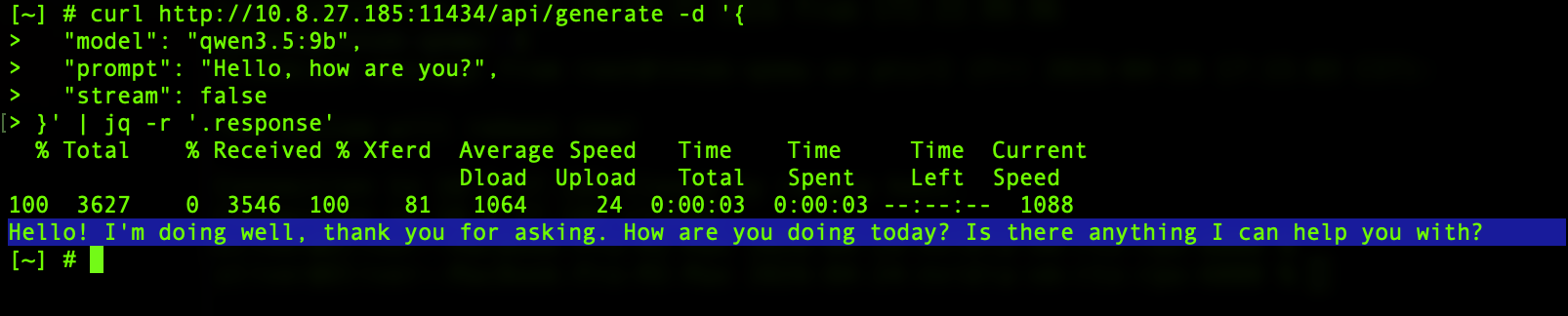
You can test the API from any device on your local network:
curl http://<NAS-IP>:11434/api/generate -d '{
"model": "qwen3.5:9b",
"prompt": "Hello, how are you?",
"stream": false
}'
Important
The OLLAMA_HOST=0.0.0.0 setting exposes the Ollama API on all network interfaces. Do not expose port 11434 to the internet. Use firewall rules or QNAP's network settings to restrict access to your local network only.
Troubleshooting
Container exits immediately after starting
This may be caused by insufficient RAM or GPU driver mismatch. Check container logs in Container Station. Reduce memory limitations or disable GPU mode.
Model pull fails midway
This may result from insufficient disk space or network timeout. Try to free up storage space. Re-run ollama pull; the system resumes from where it stopped.
Response speed is very slow (1–3 tokens per second)
The model may be running on CPU instead of GPU, or the model is too large for your RAM. Verify your GPU access with nvidia-smi inside the container. Try to use a smaller model.
The NAS becomes unresponsive during inference
This can be an "out of memory" issue: the model is consuming all the system memory. We recommend restarting the NAS. Set a memory usage limit in the application. Or use a smaller model.
"Cannot connect to Ollama" message from Open WebUI
This may be caused by a wrong API URL or Docker network isolation. You can use http://ollama:11434 if you are on the same Docker network.
適用產品
QTS,QuTS hero
Container Station
情境
您希望在 QNAP NAS 上本地運行大型語言模型(LLMs),以進行私人 AI 聊天、代碼協助或文件分析,而不將數據發送到雲端。Ollama 是最受歡迎且對初學者友好的推理引擎。本教程說明如何使用 Container Station 在 QNAP NAS 上部署 Ollama。
系統需求
| 需求 | 詳細資訊 |
|---|
| QNAP 應用程式 | Container Station 3.x 或更高版本 |
| NAS 架構 | x86_64(Intel 或 AMD CPU)
(僅支持少數 ARM 架構型號。) |
| 記憶體 | - 至少 8 GB(適用於 3B 型號)
- 至少 16 GB(適用於 7B 型號)
|
| 儲存空間空間 | - 除了模型文件大小外,至少需要 20 GB 的額外儲存空間空間。
- 盡可能使用 SSD 磁碟區。
|
| GPU(可選) | 兼容的 NVIDIA GPU(請參閱相容性清單)
GPU 應在控制台中設置為 Container Station 模式。 |
警告
OOM(內存不足)風險
Ollama 將默認嘗試將整個模型加載到內存中。如果您的 NAS 只有 8–16 GB 的 RAM,載入 14B 或更大的模型可能會耗盡系統內存,導致 NAS 服務無法響應或系統重啟。
數據丟失風險
如果您未為/root/.ollama掛載持久磁碟區,則所有下載的模型和配置在容器被移除或重建時將丟失。請務必遵循本教程中的磁碟區掛載指示。
最佳實踐
- 提前檢查模型大小與您可用的 RAM。
- 設定記憶體限制以限制容器的記憶體使用量。
- 從小型模型(1B 或 3B)開始,評估系統穩定性後再嘗試較大型的模型。
程式
方法 1:僅 CPU 部署(不需要 GPU)
建立儲存空間資料夾。
打開File Station並建立以下資料夾以存儲 Ollama 模型數據:
/share/Container/ollama
螢幕擷取畫面:File Station — 在 /share/Container/ 下建立 Ollama 資料夾
最佳實踐
如果您的 NAS 有 NVMe SSD 快取或 SSD 磁碟區,請在 SSD 上建立此資料夾。模型載入速度比 HDD 提升最多 10 倍。
建立 Docker Compose 檔案。
在 Container Station 中,前往應用程式 > 建立。命名應用程式ollama並貼上以下 YAML:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
螢幕擷取畫面:Container Station — 使用 YAML 編輯器的應用程式建立畫面
螢幕擷取畫面:Container Station — 設定記憶體限制
部署容器。
按一下建立。Container Station 會拉取 Ollama 映像並啟動容器。等待狀態顯示運行中。
螢幕截圖:Container Station — ollama 容器顯示「運行中」狀態
拉取您的第一個模型。
打開容器的終端機(或 SSH 進入您的 NAS 並執行 Docker),然後運行:
# 對於輕量級 3B 模型(建議首次測試):
ollama pull llama3.2:3b
# 對於標準 9B 模型(需要 16 GB+ RAM):
ollama pull qwen3.5:9b
下載可能需要幾分鐘,具體取決於您的網速。9B Q4_K_M 模型大約為 4–7 GB。
註
- 在拉取之前,請確認您有足夠的磁碟空間。使用
ollama list檢查現有模型及其大小。 - 對於 ARM 型 NAS 型號,我們建議從 <1B 模型開始以監控記憶體使用情況。
測試模型。
在容器終端機中執行:
ollama run qwen3.5:9b
輸入提示並確認您收到回應。輸入/bye以退出。
方法 2:NVIDIA GPU 加速部署
註
GPU 模式的額外先決條件:
- NVIDIA GPU 已安裝並由 QTS/QuTS hero 檢測到
- 在控制台中將 GPU 設置為 Container Station 模式
- 從 App Center 安裝 NVIDIA GPU 驅動程式和 NvKernelDriver
使用啟用 GPU 的 Docker Compose 配置。
將方法 1 的 YAML 替換為以下內容:
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- /share/Container/ollama:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0
- OLLAMA_KEEP_ALIVE=10m
- NVIDIA_VISIBLE_DEVICES=all
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- ai-network
networks:
ai-network:
name: ai-network
driver: bridge
截圖:Container Station — 啟用 GPU 的 Docker Compose YAML
註
QNAP 捆綁的 NVIDIA 驅動程式可能比最新版本舊。如果容器啟用 GPU 後無法啟動,請使用nvidia-smi在主機上檢查驅動程式版本,並確保其與 Ollama 映像版本兼容
部署並驗證 GPU 訪問。
容器啟動後,開啟其終端並執行:
nvidia-smi
您應該看到您的 GPU 型號、驅動程式版本和記憶體資訊。
拉取模型並確認 GPU 加速。
ollama pull qwen3.5:9b
ollama run qwen3.5:9b
在模型生成回應時,打開另一個終端並運行nvidia-smi。您應該觀察到 GPU 記憶體使用量和 GPU 利用率增加。
結果
完成本教程後,您將擁有:
- Ollama 在您的 QNAP NAS 上運行於
http://<NAS-IP>:11434 - 模型數據持久化於
/share/Container/ollama(容器重建後仍然存在) - 可透過 Ollama API 訪問的工作 LLM
您可以從本地網路上的任何裝置測試 API:
curl http://<nas-ip>:11434/api/generate -d '{"model":"qwen3.5:9b","prompt":"Hello, how are you?","stream": false}'
重要
OLLAMA_HOST=0.0.0.0設定將 Ollama API 暴露於所有網絡接口。請勿將端口 11434 暴露於互聯網。使用防火牆規則或 QNAP 的網絡設置限制僅本地網絡訪問。
故障排除
容器啟動後立即退出
這可能是由於 RAM 不足或 GPU 驅動程序不匹配造成的。檢查 Container Station 中的容器日誌。減少內存限制或禁用 GPU 模式。
模型拉取中途失敗
這可能是由於磁盤空間不足或網絡超時造成的。嘗試釋放儲存空間空間。重新運行ollama pull;系統會從停止的地方恢復。
響應速度非常慢(每秒 1–3 個 token)
模型可能在 CPU 上運行而不是 GPU,或者模型對於您的 RAM 來說太大。使用容器內的nvidia-smi驗證您的 GPU 訪問。嘗試使用較小的模型。
NAS 在推論期間變得無反應
這可能是“記憶體不足”問題:模型消耗了所有系統記憶體。我們建議重啟 NAS。在應用程式中設定記憶體使用限制。或者使用較小的模型。
Open WebUI 顯示“無法連線到 Ollama”訊息
這可能是由於 API URL 錯誤或 Docker 網絡隔離造成的。如果您在同一 Docker 網絡中,可以使用http://ollama:11434。





